Query Classifier Tutorial
![]()
In this tutorial we introduce the query classifier the goal of introducing this feature was to optimize the overall flow of Haystack pipeline by detecting the nature of user queries. Now, the Haystack can detect primarily three types of queries using both light-weight SKLearn Gradient Boosted classifier or Transformer based more robust classifier. The three categories of queries are as follows:
1. Keyword Queries:
Such queries don't have semantic meaning and merely consist of keywords. For instance these three are the examples of keyword queries.
- arya stark father
- jon snow country
- arya stark younger brothers
2. Interrogative Queries:
In such queries users usually ask a question, regardless of presence of "?" in the query the goal here is to detect the intent of the user whether any question is asked or not in the query. For example:
- who is the father of arya stark ?
- which country was jon snow filmed ?
- who are the younger brothers of arya stark ?
3. Declarative Queries:
Such queries are variation of keyword queries, however, there is semantic relationship between words. Fo example:
- Arya stark was a daughter of a lord.
- Jon snow was filmed in a country in UK.
- Bran was brother of a princess.
In this tutorial, you will learn how the TransformersQueryClassifier and SklearnQueryClassifier classes can be used to intelligently route your queries, based on the nature of the user query. Also, you can choose between a lightweight Gradients boosted classifier or a transformer based classifier.
Furthermore, there are two types of classifiers you can use out of the box from Haystack.
- Keyword vs Statement/Question Query Classifier
- Statement vs Question Query Classifier
As evident from the name the first classifier detects the keywords search queries and semantic statements like sentences/questions. The second classifier differentiates between question based queries and declarative sentences.
Prepare environment
Colab: Enable the GPU runtime
Make sure you enable the GPU runtime to experience decent speed in this tutorial.
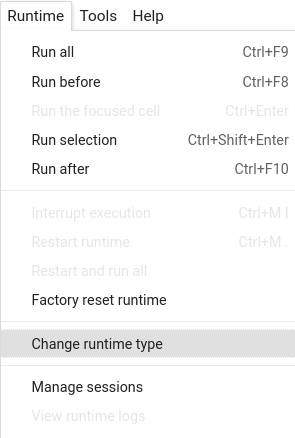
Runtime -> Change Runtime type -> Hardware accelerator -> GPU
These lines are to install Haystack through pip
# Install the latest release of Haystack in your own environment
#! pip install farm-haystack
# Install the latest master of Haystack
!pip install --upgrade pip
!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab]
# Install pygraphviz
!apt install libgraphviz-dev
!pip install pygraphviz
# In Colab / No Docker environments: Start Elasticsearch from source
! wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.2-linux-x86_64.tar.gz -q
! tar -xzf elasticsearch-7.9.2-linux-x86_64.tar.gz
! chown -R daemon:daemon elasticsearch-7.9.2
import os
from subprocess import Popen, PIPE, STDOUT
es_server = Popen(
["elasticsearch-7.9.2/bin/elasticsearch"], stdout=PIPE, stderr=STDOUT, preexec_fn=lambda: os.setuid(1) # as daemon
)
# wait until ES has started
! sleep 30
If running from Colab or a no Docker environment, you will want to start Elasticsearch from source
Initialization
Here are some core imports
Then let's fetch some data (in this case, pages from the Game of Thrones wiki) and prepare it so that it can
be used indexed into our DocumentStore
from haystack.utils import (
print_answers,
print_documents,
fetch_archive_from_http,
convert_files_to_docs,
clean_wiki_text,
launch_es,
)
from haystack.pipelines import Pipeline
from haystack.document_stores import ElasticsearchDocumentStore
from haystack.nodes import (
BM25Retriever,
EmbeddingRetriever,
FARMReader,
TransformersQueryClassifier,
SklearnQueryClassifier,
)
# Download and prepare data - 517 Wikipedia articles for Game of Thrones
doc_dir = "data/tutorial14"
s3_url = "https://s3.eu-central-1.amazonaws.com/deepset.ai-farm-qa/datasets/documents/wiki_gameofthrones_txt14.zip"
fetch_archive_from_http(url=s3_url, output_dir=doc_dir)
# convert files to dicts containing documents that can be indexed to our datastore
got_docs = convert_files_to_docs(dir_path=doc_dir, clean_func=clean_wiki_text, split_paragraphs=True)
# Initialize DocumentStore and index documents
launch_es()
document_store = ElasticsearchDocumentStore()
document_store.delete_documents()
document_store.write_documents(got_docs)
# Initialize Sparse retriever
bm25_retriever = BM25Retriever(document_store=document_store)
# Initialize dense retriever
embedding_retriever = EmbeddingRetriever(
document_store=document_store,
model_format="sentence_transformers",
embedding_model="sentence-transformers/multi-qa-mpnet-base-dot-v1",
)
document_store.update_embeddings(embedding_retriever, update_existing_embeddings=False)
reader = FARMReader(model_name_or_path="deepset/roberta-base-squad2")
Keyword vs Question/Statement Classifier
The keyword vs question/statement query classifier essentially distinguishes between the keyword queries and statements/questions. So you can intelligently route to different retrieval nodes based on the nature of the query. Using this classifier can potentially yield the following benefits:
- Getting better search results (e.g. by routing only proper questions to DPR / QA branches and not keyword queries)
- Less GPU costs (e.g. if 50% of your traffic is only keyword queries you could just use elastic here and save the GPU resources for the other 50% of traffic with semantic queries)
Below, we define a SklearnQueryClassifier and show how to use it:
Read more about the trained model and dataset used here
# Here we build the pipeline
sklearn_keyword_classifier = Pipeline()
sklearn_keyword_classifier.add_node(component=SklearnQueryClassifier(), name="QueryClassifier", inputs=["Query"])
sklearn_keyword_classifier.add_node(
component=embedding_retriever, name="EmbeddingRetriever", inputs=["QueryClassifier.output_1"]
)
sklearn_keyword_classifier.add_node(component=bm25_retriever, name="ESRetriever", inputs=["QueryClassifier.output_2"])
sklearn_keyword_classifier.add_node(component=reader, name="QAReader", inputs=["ESRetriever", "EmbeddingRetriever"])
sklearn_keyword_classifier.draw("pipeline_classifier.png")
# Run only the dense retriever on the full sentence query
res_1 = sklearn_keyword_classifier.run(query="Who is the father of Arya Stark?")
print("Embedding Retriever Results" + "\n" + "=" * 15)
print_answers(res_1, details="minimum")
# Run only the sparse retriever on a keyword based query
res_2 = sklearn_keyword_classifier.run(query="arya stark father")
print("ES Results" + "\n" + "=" * 15)
print_answers(res_2, details="minimum")
# Run only the dense retriever on the full sentence query
res_3 = sklearn_keyword_classifier.run(query="which country was jon snow filmed ?")
print("Embedding Retriever Results" + "\n" + "=" * 15)
print_answers(res_3, details="minimum")
# Run only the sparse retriever on a keyword based query
res_4 = sklearn_keyword_classifier.run(query="jon snow country")
print("ES Results" + "\n" + "=" * 15)
print_answers(res_4, details="minimum")
# Run only the dense retriever on the full sentence query
res_5 = sklearn_keyword_classifier.run(query="who are the younger brothers of arya stark ?")
print("Embedding Retriever Results" + "\n" + "=" * 15)
print_answers(res_5, details="minimum")
# Run only the sparse retriever on a keyword based query
res_6 = sklearn_keyword_classifier.run(query="arya stark younger brothers")
print("ES Results" + "\n" + "=" * 15)
print_answers(res_6, details="minimum")
Transformer Keyword vs Question/Statement Classifier
Firstly, it's essential to understand the trade-offs between SkLearn and Transformer query classifiers. The transformer classifier is more accurate than SkLearn classifier however, it requires more memory and most probably GPU for faster inference however the transformer size is roughly 50 MBs. Whereas, SkLearn is less accurate however is much more faster and doesn't require GPU for inference.
Below, we define a TransformersQueryClassifier and show how to use it:
Read more about the trained model and dataset used here
# Here we build the pipeline
transformer_keyword_classifier = Pipeline()
transformer_keyword_classifier.add_node(
component=TransformersQueryClassifier(), name="QueryClassifier", inputs=["Query"]
)
transformer_keyword_classifier.add_node(
component=embedding_retriever, name="EmbeddingRetriever", inputs=["QueryClassifier.output_1"]
)
transformer_keyword_classifier.add_node(
component=bm25_retriever, name="ESRetriever", inputs=["QueryClassifier.output_2"]
)
transformer_keyword_classifier.add_node(component=reader, name="QAReader", inputs=["ESRetriever", "EmbeddingRetriever"])
transformer_keyword_classifier.draw("pipeline_classifier.png")
# Run only the dense retriever on the full sentence query
res_1 = transformer_keyword_classifier.run(query="Who is the father of Arya Stark?")
print("Embedding Retriever Results" + "\n" + "=" * 15)
print_answers(res_1, details="minimum")
# Run only the sparse retriever on a keyword based query
res_2 = transformer_keyword_classifier.run(query="arya stark father")
print("ES Results" + "\n" + "=" * 15)
print_answers(res_2, details="minimum")
# Run only the dense retriever on the full sentence query
res_3 = transformer_keyword_classifier.run(query="which country was jon snow filmed ?")
print("Embedding Retriever Results" + "\n" + "=" * 15)
print_answers(res_3, details="minimum")
# Run only the sparse retriever on a keyword based query
res_4 = transformer_keyword_classifier.run(query="jon snow country")
print("ES Results" + "\n" + "=" * 15)
print_answers(res_4, details="minimum")
# Run only the dense retriever on the full sentence query
res_5 = transformer_keyword_classifier.run(query="who are the younger brothers of arya stark ?")
print("Embedding Retriever Results" + "\n" + "=" * 15)
print_answers(res_5, details="minimum")
# Run only the sparse retriever on a keyword based query
res_6 = transformer_keyword_classifier.run(query="arya stark younger brothers")
print("ES Results" + "\n" + "=" * 15)
print_answers(res_6, details="minimum")
Question vs Statement Classifier
One possible use case of this classifier could be to route queries after the document retrieval to only send questions to QA reader and in case of declarative sentence, just return the DPR/ES results back to user to enhance user experience and only show answers when user explicitly asks it.
Below, we define a TransformersQueryClassifier and show how to use it:
Read more about the trained model and dataset used here
# Here we build the pipeline
transformer_question_classifier = Pipeline()
transformer_question_classifier.add_node(component=embedding_retriever, name="EmbeddingRetriever", inputs=["Query"])
transformer_question_classifier.add_node(
component=TransformersQueryClassifier(model_name_or_path="shahrukhx01/question-vs-statement-classifier"),
name="QueryClassifier",
inputs=["EmbeddingRetriever"],
)
transformer_question_classifier.add_node(component=reader, name="QAReader", inputs=["QueryClassifier.output_1"])
transformer_question_classifier.draw("question_classifier.png")
# Run only the QA reader on the question query
res_1 = transformer_question_classifier.run(query="Who is the father of Arya Stark?")
print("Embedding Retriever Results" + "\n" + "=" * 15)
print_answers(res_1, details="minimum")
res_2 = transformer_question_classifier.run(query="Arya Stark was the daughter of a Lord.")
print("ES Results" + "\n" + "=" * 15)
print_documents(res_2)
Standalone Query Classifier
Below we run queries classifiers standalone to better understand their outputs on each of the three types of queries
# Here we create the keyword vs question/statement query classifier
from haystack.nodes import TransformersQueryClassifier
queries = [
"arya stark father",
"jon snow country",
"who is the father of arya stark",
"which country was jon snow filmed?",
]
keyword_classifier = TransformersQueryClassifier()
for query in queries:
result = keyword_classifier.run(query=query)
if result[1] == "output_1":
category = "question/statement"
else:
category = "keyword"
print(f"Query: {query}, raw_output: {result}, class: {category}")
# Here we create the question vs statement query classifier
from haystack.nodes import TransformersQueryClassifier
queries = [
"Lord Eddard was the father of Arya Stark.",
"Jon Snow was filmed in United Kingdom.",
"who is the father of arya stark?",
"Which country was jon snow filmed in?",
]
question_classifier = TransformersQueryClassifier(model_name_or_path="shahrukhx01/question-vs-statement-classifier")
for query in queries:
result = question_classifier.run(query=query)
if result[1] == "output_1":
category = "question"
else:
category = "statement"
print(f"Query: {query}, raw_output: {result}, class: {category}")
Conclusion
The query classifier gives you more possibility to be more creative with the pipelines and use different retrieval nodes in a flexible fashion. Moreover, as in the case of Question vs Statement classifier you can also choose the queries which you want to send to the reader.
Finally, you also have the possible of bringing your own classifier and plugging it into either TransformersQueryClassifier(model_name_or_path="<huggingface_model_name_or_file_path>") or using the SklearnQueryClassifier(model_name_or_path="url_to_classifier_or_file_path_as_pickle", vectorizer_name_or_path="url_to_vectorizer_or_file_path_as_pickle")
About us
This Haystack notebook was made with love by deepset in Berlin, Germany
We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our other work:
Get in touch: Twitter | LinkedIn | Slack | GitHub Discussions | Website
By the way: we're hiring!