Better Retrieval via "Dense Passage Retrieval"
![]()
Importance of Retrievers
The Retriever has a huge impact on the performance of our overall search pipeline.
Different types of Retrievers
Sparse
Family of algorithms based on counting the occurrences of words (bag-of-words) resulting in very sparse vectors with length = vocab size.
Examples: BM25, TF-IDF
Pros: Simple, fast, well explainable
Cons: Relies on exact keyword matches between query and text
Dense
These retrievers use neural network models to create "dense" embedding vectors. Within this family there are two different approaches:
a) Single encoder: Use a single model to embed both query and passage.
b) Dual-encoder: Use two models, one to embed the query and one to embed the passage
Recent work suggests that dual encoders work better, likely because they can deal better with the different nature of query and passage (length, style, syntax ...).
Examples: REALM, DPR, Sentence-Transformers
Pros: Captures semantinc similarity instead of "word matches" (e.g. synonyms, related topics ...)
Cons: Computationally more heavy, initial training of model
"Dense Passage Retrieval"
In this Tutorial, we want to highlight one "Dense Dual-Encoder" called Dense Passage Retriever. It was introdoced by Karpukhin et al. (2020, https://arxiv.org/abs/2004.04906.
Original Abstract:
"Open-domain question answering relies on efficient passage retrieval to select candidate contexts, where traditional sparse vector space models, such as TF-IDF or BM25, are the de facto method. In this work, we show that retrieval can be practically implemented using dense representations alone, where embeddings are learned from a small number of questions and passages by a simple dual-encoder framework. When evaluated on a wide range of open-domain QA datasets, our dense retriever outperforms a strong Lucene-BM25 system largely by 9%-19% absolute in terms of top-20 passage retrieval accuracy, and helps our end-to-end QA system establish new state-of-the-art on multiple open-domain QA benchmarks."
Paper: https://arxiv.org/abs/2004.04906
Original Code: https://fburl.com/qa-dpr
Use this link to open the notebook in Google Colab.
Prepare environment
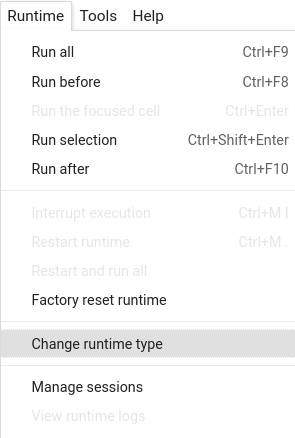
Colab: Enable the GPU runtime
Make sure you enable the GPU runtime to experience decent speed in this tutorial.
Runtime -> Change Runtime type -> Hardware accelerator -> GPU
# Make sure you have a GPU running
!nvidia-smi
# Install the latest release of Haystack in your own environment
#! pip install farm-haystack
# Install the latest master of Haystack
!pip install --upgrade pip
!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,faiss]
from haystack.utils import clean_wiki_text, convert_files_to_docs, fetch_archive_from_http, print_answers
from haystack.nodes import FARMReader, TransformersReader
Document Store
Option 1: FAISS
FAISS is a library for efficient similarity search on a cluster of dense vectors.
The FAISSDocumentStore uses a SQL(SQLite in-memory be default) database under-the-hood
to store the document text and other meta data. The vector embeddings of the text are
indexed on a FAISS Index that later is queried for searching answers.
The default flavour of FAISSDocumentStore is "Flat" but can also be set to "HNSW" for
faster search at the expense of some accuracy. Just set the faiss_index_factor_str argument in the constructor.
For more info on which suits your use case: https://github.com/facebookresearch/faiss/wiki/Guidelines-to-choose-an-index
from haystack.document_stores import FAISSDocumentStore
document_store = FAISSDocumentStore(faiss_index_factory_str="Flat")
Option 2: Milvus
Milvus is an open source database library that is also optimized for vector similarity searches like FAISS. Like FAISS it has both a "Flat" and "HNSW" mode but it outperforms FAISS when it comes to dynamic data management. It does require a little more setup, however, as it is run through Docker and requires the setup of some config files. See their docs for more details.
# Milvus cannot be run on COlab, so this cell is commented out.
# To run Milvus you need Docker (versions below 2.0.0) or a docker-compose (versions >= 2.0.0), neither of which is available on Colab.
# See Milvus' documentation for more details: https://milvus.io/docs/install_standalone-docker.md
# !pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[milvus]
# from haystack.utils import launch_milvus
# from haystack.document_stores import MilvusDocumentStore
# launch_milvus()
# document_store = MilvusDocumentStore()
Cleaning & indexing documents
Similarly to the previous tutorials, we download, convert and index some Game of Thrones articles to our DocumentStore
# Let's first get some files that we want to use
doc_dir = "data/tutorial6"
s3_url = "https://s3.eu-central-1.amazonaws.com/deepset.ai-farm-qa/datasets/documents/wiki_gameofthrones_txt6.zip"
fetch_archive_from_http(url=s3_url, output_dir=doc_dir)
# Convert files to dicts
docs = convert_files_to_docs(dir_path=doc_dir, clean_func=clean_wiki_text, split_paragraphs=True)
# Now, let's write the dicts containing documents to our DB.
document_store.write_documents(docs)
Initalize Retriever, Reader & Pipeline
Retriever
Here: We use a DensePassageRetriever
Alternatives:
- The
BM25Retrieverwith custom queries (e.g. boosting) and filters - Use
EmbeddingRetrieverto find candidate documents based on the similarity of embeddings (e.g. created via Sentence-BERT) - Use
TfidfRetrieverin combination with a SQL or InMemory Document store for simple prototyping and debugging
from haystack.nodes import DensePassageRetriever
retriever = DensePassageRetriever(
document_store=document_store,
query_embedding_model="facebook/dpr-question_encoder-single-nq-base",
passage_embedding_model="facebook/dpr-ctx_encoder-single-nq-base",
max_seq_len_query=64,
max_seq_len_passage=256,
batch_size=16,
use_gpu=True,
embed_title=True,
use_fast_tokenizers=True,
)
# Important:
# Now that after we have the DPR initialized, we need to call update_embeddings() to iterate over all
# previously indexed documents and update their embedding representation.
# While this can be a time consuming operation (depending on corpus size), it only needs to be done once.
# At query time, we only need to embed the query and compare it the existing doc embeddings which is very fast.
document_store.update_embeddings(retriever)
Reader
Similar to previous Tutorials we now initalize our reader.
Here we use a FARMReader with the deepset/roberta-base-squad2 model (see: https://huggingface.co/deepset/roberta-base-squad2)
FARMReader
# Load a local model or any of the QA models on
# Hugging Face's model hub (https://huggingface.co/models)
reader = FARMReader(model_name_or_path="deepset/roberta-base-squad2", use_gpu=True)
Pipeline
With a Haystack Pipeline you can stick together your building blocks to a search pipeline.
Under the hood, Pipelines are Directed Acyclic Graphs (DAGs) that you can easily customize for your own use cases.
To speed things up, Haystack also comes with a few predefined Pipelines. One of them is the ExtractiveQAPipeline that combines a retriever and a reader to answer our questions.
You can learn more about Pipelines in the docs.
from haystack.pipelines import ExtractiveQAPipeline
pipe = ExtractiveQAPipeline(reader, retriever)
Voilà! Ask a question!
# You can configure how many candidates the reader and retriever shall return
# The higher top_k for retriever, the better (but also the slower) your answers.
prediction = pipe.run(
query="Who created the Dothraki vocabulary?", params={"Retriever": {"top_k": 10}, "Reader": {"top_k": 5}}
)
print_answers(prediction, details="minimum")
About us
This Haystack notebook was made with love by deepset in Berlin, Germany
We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our other work:
Get in touch: Twitter | LinkedIn | Slack | GitHub Discussions | Website
By the way: we're hiring!